
I obtained my Electrical and Computer Engineering PhD degree from The University of Texas at Austin, with my ambitious goal of building a general AI for human benefits. I am privileged to work with Prof.Peter Stone at the Learning Agent Research Group (LARG). Priviously I completed my undergraduate study at Shanghai Jiao Tong University with a major in Mechanical Engineering (Robotics). I broadened my practical AI skillset through an enriching internship under Xiaomeng Yang and Yuandong Tian at Meta FAIR Labs in Summer 2022. Besides research, I enjoy Tennis, Cello and Rap Music. I dedicate one hour each week to exchanging ideas and offering mentorship. Please book a meeting here if you are interested in chatting with me.
My current research interests include:
I coordinate Reinforcement Learning Reading Group (RLRG) at UT.
Academic Services: reviewer for NeurIPS, ICML, ICLR, AAMAS, CVPR, RA-L
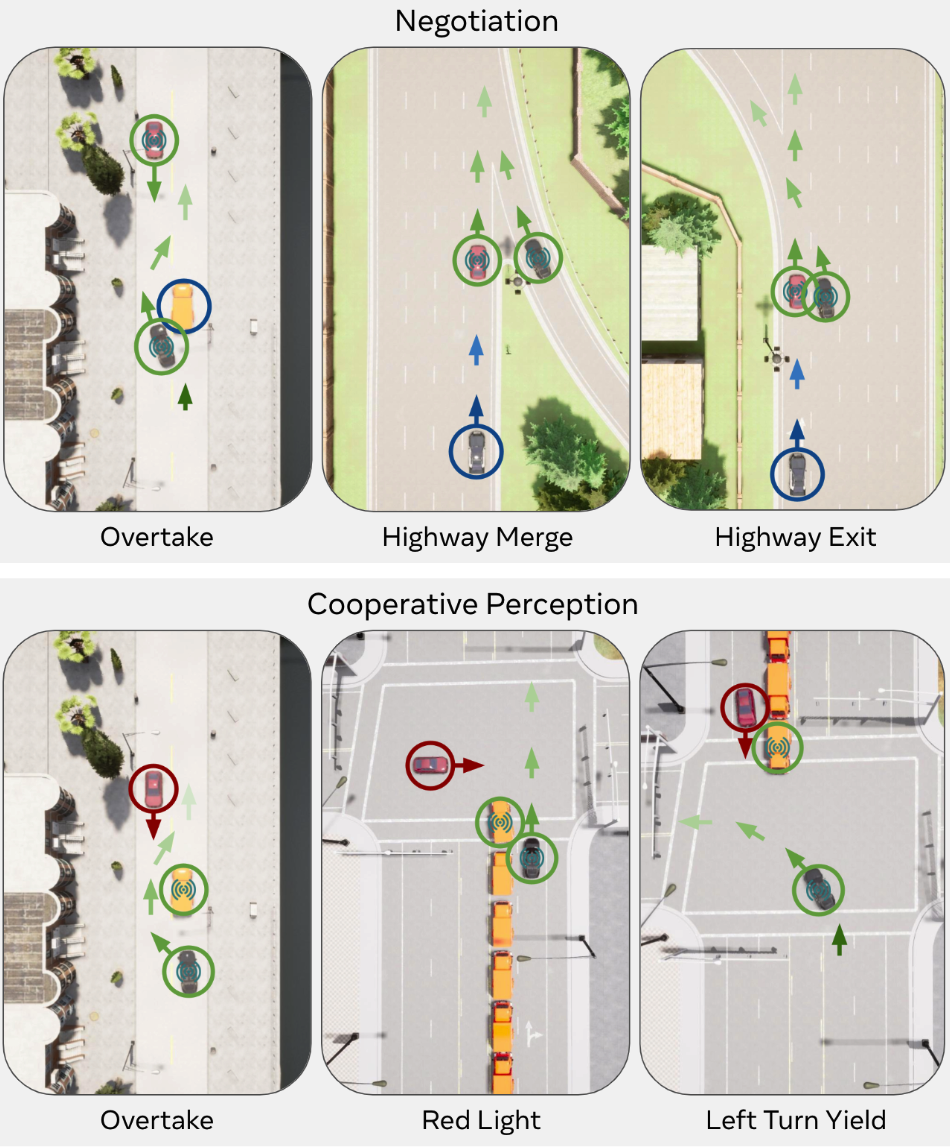
CoopReflect: Towards Natural Language Communication for Cooperative Autonomous Driving via Multi-Agent Learning
Jiaxun Cui, Chen Tang, Jarrett Holtz, Janice Nguyen, Alessandro G. Allievi, Hang Qiu, Peter Stone
The 25th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS Oral), 2026
[project page] [paper] [code] [slides]
Using natural language as a vehicle-to-vehicle (V2V) communication protocol offers the potential for autonomous vehicles to drive cooperatively not only with each other but also with human drivers. We develop LLM-based driving agents and study their interactions in a new simulation environment, TalkingVehiclesGym, and introduce CoopReflect, a multi-agent learning framework that equips agents with knowledge for both natural language message generation and high-level decision-making through trial and error and multi-agent debriefing. Experiments show that CoopReflect produces more meaningful and human-understandable messages than existing baselines, enabling stronger cooperation.
Earlier version at WMAC 2025 (Oral). [workshop paper]
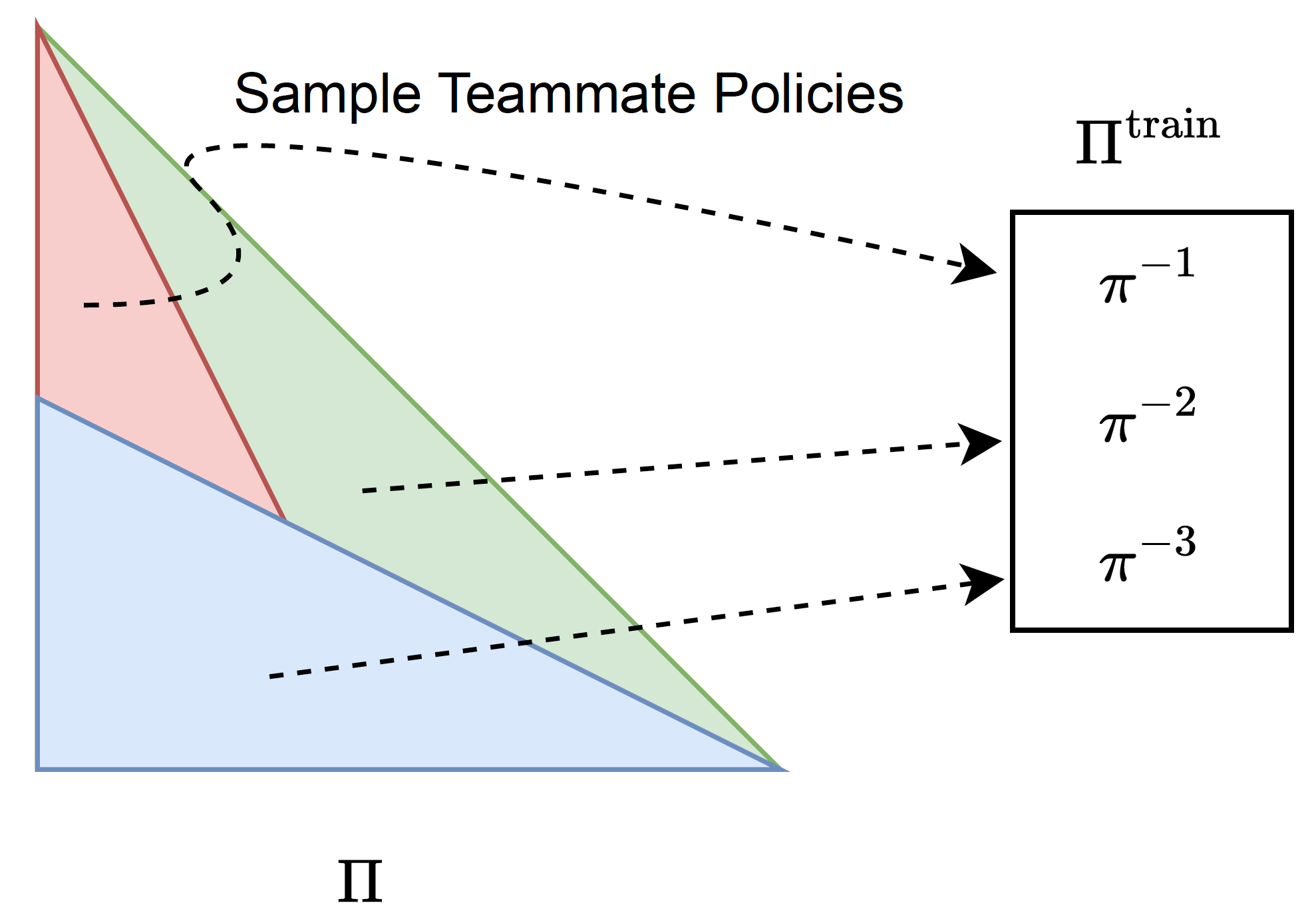
Minimum Coverage Sets for Training Robust Ad Hoc Teamwork Agents
Arrasy Rahman, Jiaxun Cui, Peter Stone
Annual AAAI Conference on Artificial Intelligence (AAAI), 2024
[paper] [code]
In this work, we first propose that maximizing an AHT agent's robustness requires it to emulate policies in the minimum coverage set (MCS), the set of best-response policies to any partner policies in the environment. We then introduce the L-BRDiv algorithm that generates a set of teammate policies that, when used for AHT training, encourage agents to emulate policies from the MCS. L-BRDiv works by solving a constrained optimization problem to jointly train teammate policies for AHT training and approximating AHT agent policies that are members of the MCS.
MACTA: A Multi-agent Reinforcement Learning Approach for Cache Timing Attacks and Detection
Jiaxun Cui, Xiaomeng Yang*, Mulong Luo*, Geunbae Lee*, Peter Stone, Hsien-Hsin S Lee, Benjamin Lee, G Edward Suh, Wenjie Xiong*, Yuandong Tian*
International Conference on Learning Representations (ICLR), 2023
[paper] [code]
MACTA detectors can generalize to a heuristic attack not exposed in training with a 97.8% detection rate and reduce the attack bandwidth of adaptive attackers by 20% on average. In the meantime, MACTA attackers are qualitatively more effective than other attacks studied, and the average evasion rate of MACTA attackers against an unseen state-of-the-art detector can reach up to 99%.
Coopernaut: End-to-End Driving with Cooperative Perception for Networked Vehicles
Jiaxun Cui*, Hang Qiu*, Dian Chen, Peter Stone, Yuke Zhu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
[project page] [paper] [code]
There are dangerous scenarios where single optical based sensor are occluded. We develop a series of benchmark scenarios in the CARLA simulator where cooperative perception can make big difference in the decisions made by the autonomous vehicles.
Meta-Learning for Multiround Chinese Standard Mahjong Game
Chinese Standard Mahjong Game is a 4-player zero-sum imperfect information game. While in the formal competitions of the mahjong game, a player will compete with the other opponents for a fixed number of rounds, and then the relative cumulative reward/points are compared. It is no longer a zero-sum game and the agents only care about a relative better performance than other players. This competition mechanism induces multi-round tactics. For example, an agent may play conservatively to secure its ranking or play riskly when it is left behind.
Scalable Multiagent Driving Policies For Reducing Traffic Congestion
Jiaxun Cui, William Macke, Harel Yedidsion, Aastha Goyal, Daniel Urielli, Peter Stone
Oral Presentation, International Conference on Autonomous Agents and Multiagent Systems (AAMAS Oral), 2021
[paper]
[code]
In the mordern highway system, the issue of conjestions brings inefficiency in traffic throughput and also cause waste of energy consumption. In this project, we employed deep Reinforcement Learning method to alleviate stop-and-go waves arosed from merging. We explored two aspects of multi-agent learning: Centralized and Distributed. Evaluting only average speed and throughput efficiency could be toublesome because the two metrics may not be improved at the same time. Thus, we developed a new metric: time delay for a certain number of vehicles to enter and exit the networks.